Building a continuous GOES-17 brightness temperature time series over a single point
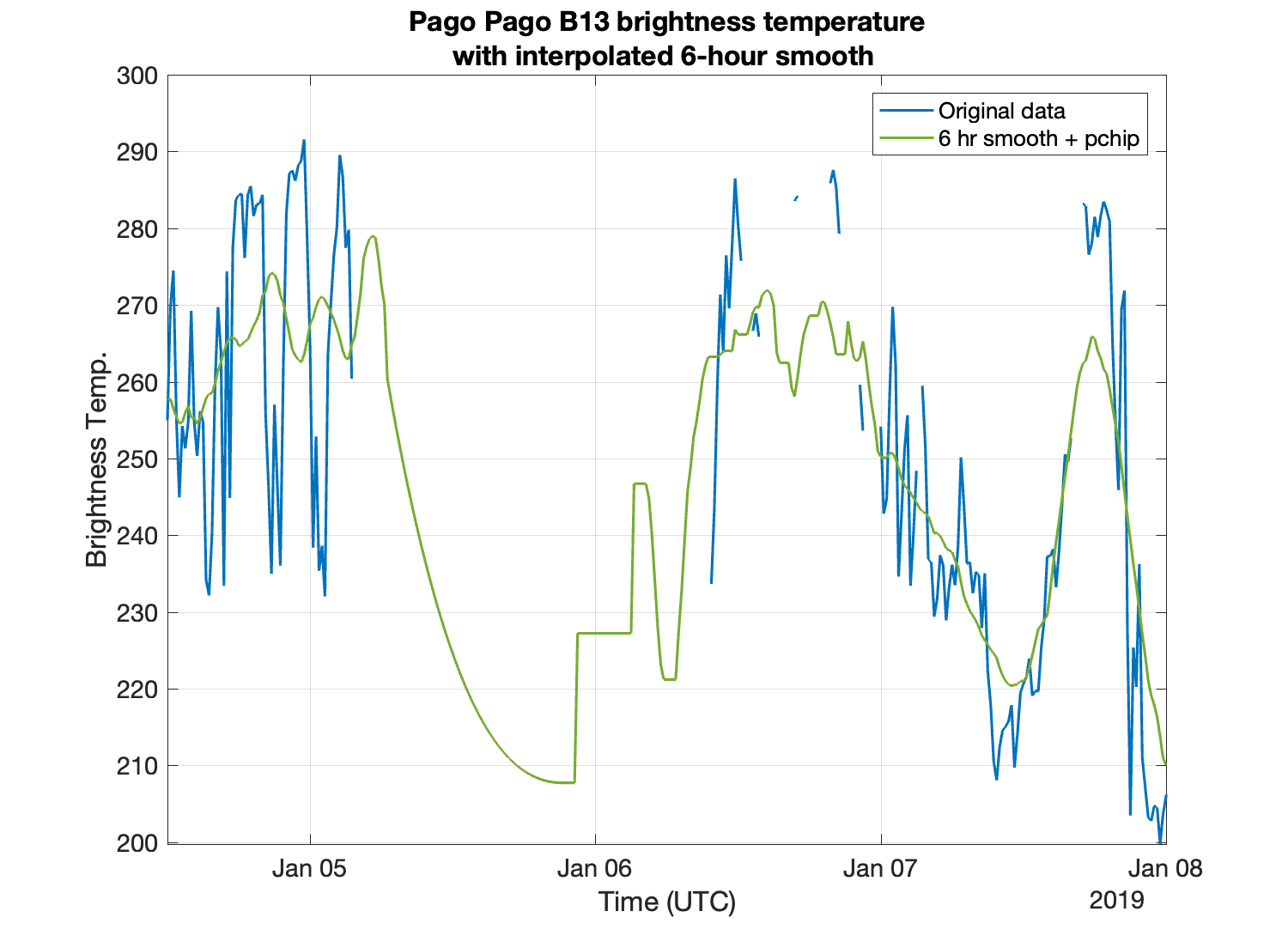
This post explores data-filling methods for missing data in a GOES-17 Level 1B radiance time series dataset.Background: SSEC’s Data Center is home to a near complete record of GOES-16 and GOES-17 Full Disk Level 1B data. With these data capabilities, it is possible to compile a time series or ‘short climatology’ of GOES data... Read More
